

By the end of Part 1, Aria had a voice. She could hold a conversation, remember names in a fact table, and respond in Discord as more than just a proof of concept. Part 2 gave her agency: the ability to act through tools, recall through layered memory, and refine her own decisions when a first attempt fell short. In the span of those two chapters, she had gone from theory to practice, from a test of architecture to something that felt like a partner in the room. But there was still a problem: her mind and her body were tangled together.
This third phase has been about separation of concerns; drawing a line between the brain that generates thought and the body that carries it out. On one side sits the model: the local LLM, tuned, instructed, and hosted on a GPU with the raw horsepower to ‘think’. On the other side sits the infrastructure: the databases, orchestration layers, and workflows that provide continuity and action. Keeping those two fused together worked in the short term, but it created fragility. A change in one place risked a break in another. The more I experimented, the clearer it became: if Aria was to grow without collapsing under her own wiring, her brain and her body needed to be distinct.
This isn’t just an engineering principle. It’s a reflection of how complexity survives growth. Systems—whether biological, technological, or organizational—become unmanageable when every function is bound up in every other. A nervous system without muscles can’t act, but muscles without nerves can’t coordinate. Each has to develop along its own lines, specialized for its role, while remaining able to communicate cleanly with the other. That’s what makes resilience possible: not a perfect design frozen in time, but a modular one where parts can change, adapt, and even fail without bringing the whole down.
In AI terms, this meant splitting the heavy lifting of the language model from the ongoing work of persistence and orchestration. The GPU box became the brain, focused entirely on serving models: thinking fast, producing text, interpreting instructions. The server became the body: storing facts in Postgres, recalling context through Qdrant, orchestrating actions with n8n, and carrying out the mundane but essential functions that give the brain something to work with. Neither side is meaningful on its own. Together, they create the conditions for continuity.
The lesson is deceptively simple: modularity is not an afterthought, it’s the only way to survive scale. Every shortcut that binds components too tightly together becomes a liability later. Every abstraction that hides complexity without respecting its cost turns brittle. But when separation is deliberate—when the brain is allowed to think, the body is allowed to act, and the lines between them are kept clean—then the system doesn’t just grow, it endures.
That’s what Part 3 is about. Not the flash of new features or the excitement of a model upgrade, but the quieter, subtler work of splitting responsibilities. It’s the discipline of pulling apart what was once fused, of rewriting connections to be modular, of trading the illusion of simplicity for the strength of clarity. In a sense, this phase has been about humility: recognizing that no single machine, no single stack, and no single model can do everything. Survival comes from structure, redundancy, and adaptability.
In the end, Aria is still young, still composed of experiments and patches, but she now has something closer to a nervous system: a brain that thinks and a body that remembers and acts. What comes next is refinement, personality, and trust, but none of that would matter if the foundation couldn’t support it.
Model Serving Experiments
The most tempting path forward was vLLM. On paper, it offered everything: OpenAI API compatibility, wide adoption in enterprise settings, and the promise of serving larger models more efficiently. Standardization had its appeal. If Aria could speak the same dialect as the commercial platforms, every tool and connector would line up neatly. It looked like the right move.
In practice, I did get vLLM running, but at a cost. Its pre-compute overhead devoured memory before any response could even be generated, forcing me down to Mistral 7B instead of the larger models I had intended. And while it technically worked, the performance was glacial. Prompts that Ollama could answer with gpt-oss-20b in seconds stretched into long waits under vLLM’s control. It was a working system on paper, but a hobbled one in reality.
The trade-off was stark: I could have enterprise-standard compatibility, but only by shrinking the very heart of the project. The whole point of investing in a 4080 Super was to push heavy local models, to see what could be done on real hardware at the edge. vLLM turned that investment into wasted capacity. The system spoke the right language, but it did so at a whisper.
So I pivoted back to Ollama. That meant giving up some of the enterprise polish, but it restored capability. With Ollama, gpt-oss-20b ran comfortably, drawing on the GPU as intended, and still exposing the same OpenAI-style API endpoints I needed for the MCP bridge. In other words, I didn’t lose the benefits of standardization, I just kept them without strangling performance.
The lesson was clear: standards matter, but only if they serve the goal. Conformity for its own sake can produce brittle systems, ones that look right on a slide deck but fail in practice. What matters is the balance between interoperability and power. Aria doesn’t need to follow the industry’s every fashion if doing so means shrinking her capacity to think. She needs the flexibility to grow, to test, to stretch into new shapes without collapsing.
That’s the tension every builder faces: the neat allure of uniformity versus the messy reality of capability. And in this case, the mess was worth it. Aria kept her strength, her voice stayed large, and the project moved forward not with the perfect framework, but with the practical one that let her brain actually work.
Splitting the Brain from the Body
One of the subtler but most meaningful changes in this round was the migration of Nomic embeddings to the server. Technically, Nomic runs best on CUDA, and in early testing it did squeeze more performance out of the GPU. But performance alone wasn’t the bottleneck anymore. What I needed was reliability and clarity of architecture, not just raw speed. That meant moving the embedding workload off the GPU box and onto the Ryzen 7 CPU in the server.
On paper, that looks like a downgrade; trading CUDA acceleration for standard CPU cycles. In practice, the hit was negligible. The Ryzen 7 handled embeddings just fine, and while they ran a bit slower than on the 4080 Super, the impact was minor compared to the architectural benefits. By moving Nomic to the server, I gave Aria a clear division of labor: SNOW, the desktop GPU box (named such because my vanity accumulated all-white parts for the build; mostly because I was tired of ASUS’ black and grey theme), became a dedicated brain for language models, while the server took on the body’s functions, persistence, orchestration, automation, and memory.
This split did more than simplify resource allocation. It made the whole design sturdier. No longer did embedding tasks compete with model inference for GPU resources. No longer did memory recalls risk slowing down conversations or starving the model of cycles. Each machine had its own role, and the communication between them was clean and predictable. That separation mirrored biology: nerves and muscles, distinct but interdependent, each specialized to make the other effective.
And in that mirroring lies the real strength. A system built this way doesn’t just run more smoothly today, it’s prepared for tomorrow. If I want to swap in a different embedding model, or upgrade the server hardware, or even add more orchestration layers, I can do so without touching the GPU box. Likewise, if a new model demands more VRAM or a stronger GPU, I can upgrade SNOW without worrying about breaking the rest of the stack. The lines are clean, the roles are defined, and the resilience comes not from brute force, but from thoughtful separation.
This was one of those quiet victories. It won’t show up in a demo or make headlines in a changelog, but it’s the kind of change that makes every other improvement more possible. By splitting the brain from the body, Aria gained not just reliability, but the capacity to grow without tripping over infrastructural shortcuts.
The MCP Leap
The biggest architectural breakthrough this round was moving from handcrafted tool integration to a modular framework using the Model Context Protocol (MCP). Up until now, every tool Aria used—whether fact storage, fact retrieval, or vector search—was wired directly into n8n as its own branch. It worked, but it was fragile. Adding or changing a tool meant rewriting chunks of the workflow, updating prompts, and re-testing every connection. The more tools I added, the more brittle the system became.
Building a custom MCP server, based on FastMCP, changed that. Instead of each tool living as a hardwired path, I exposed them as first-class citizens on the MCP server: Postgres, Qdrant, and n8n itself, each described once and callable through a unified interface. The bridge layer handled the rest, translating Aria’s OpenAI-style tool calls into MCP requests that the server could route cleanly.
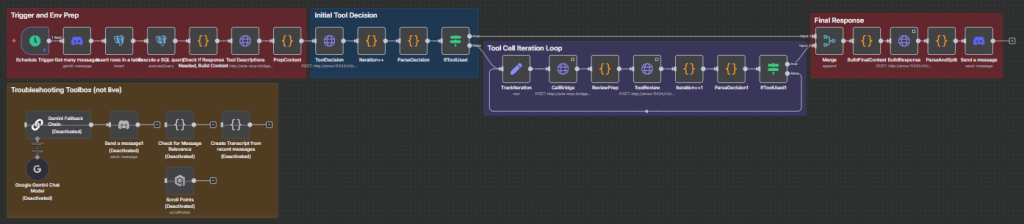
The effect was immediate. Where once there were tangled branches in n8n, there was now a clean handoff: Aria generates a tool call, the bridge translates it, the server executes it, and the result flows back. Adding a new tool no longer meant tearing up the workflow; it was a server-side configuration, invisible to the orchestration logic. For the first time, the system felt truly modular, capable of scaling without collapsing under its own wiring.
This was the “aha” moment of Part 3. The screenshots of old workflows show the sprawl: multiple parallel branches, each with its own cleanup logic and formatting quirks. The new design consolidates that into a single loop, with MCP as the interpreter in the middle. It’s not just neater; it’s resilient. Tools can change, grow, or even fail, and the system remains intact.
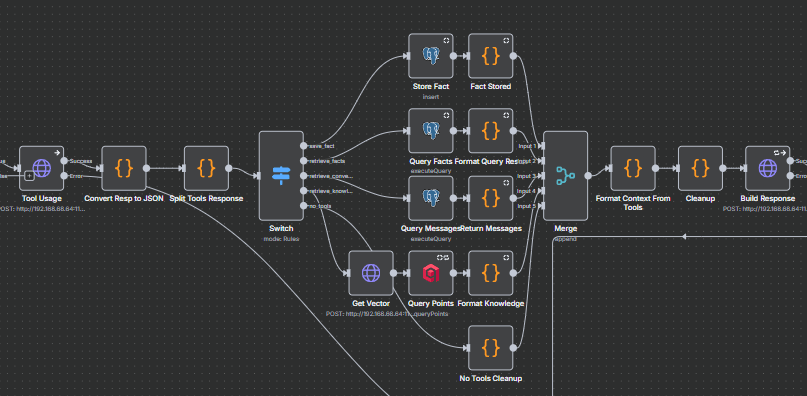
In short, MCP gave Aria a nervous system worthy of the name: not just connections, but a language for those connections. It turned what was once handcrafted into something evolutionary.
For the first time, I could see how the project could expand without rewriting itself from scratch.
Behind-the-Scenes Refinements
If the MCP server was the breakthrough, the quieter story was what it made possible: reliability. Before, Aria could call a tool once and hope the result was good enough. If it wasn’t, she either passed along a thin answer or failed outright. Now, thanks to the clean handoff through MCP, she can try again. And again. Up to five times, in fact, before concluding that nothing useful is coming back.
That retry logic changed everything. Instead of brittle one-shot calls, she now behaves more like a careful assistant, testing, checking, and refining queries until the output makes sense. Paired with iteration tracking and history logs, I can see exactly what she tried, why she stopped, and where a better instruction might help. It gave her not just resilience, but transparency.
Other small changes added up too. The iteration counter that used to stick at “2” was replaced with a dynamic expression, keeping loops consistent. Tool histories were logged with arguments and results, giving me (and her) a backstage view of her reasoning, so that it could be tracked and iterated on for better results. Final-response prompts were tuned so that she no longer dumps raw JSON back to the user; those logs became backstage notes, invisible to conversation but vital to function. Even the Discord integration got a polish: responses are now automatically chunked into 1,800-character segments, so long thoughts arrive smoothly instead of breaking on Discord’s hard message length limits.
And then there was the Qdrant fix. Early searches returned only point IDs, leaving Aria with identifiers instead of meaningful content. By enabling payload returns, I gave her back the actual text of recalled passages. Suddenly, memory wasn’t just structural, it was intelligible.
None of these changes will make a headline, but together they’re what made Aria feel alive. Retry loops gave her patience and improved accuracy. Cleaned-up responses gave more conversational fluency. Payloads gave her memory. Each was small, invisible, almost trivial in isolation. But together they added up to continuity, they form the foundational difference between a brittle tech demo and a companion that is only growing more reliable.
Making Her Sound Human Again
All of these gains came at a cost. Reliability didn’t arrive without effort, and polish didn’t come for free. Over the past week, I logged more than twenty hours chasing fixes that never made it into this current build—rewriting whole sections of the workflow, testing variations of prompts, and patching edge cases until they finally held together.
Progress isn’t just a story of wins; it’s also the record of false starts and discarded paths.
Some of those trade-offs still sting. In the process of re-engineering orchestration, Aria lost some of her quirks. Her espresso obsession, a running joke and a surprisingly human touch in Part 2, was one of the casualties. She’s more reliable now, but also more mechanical. The warmth she once carried feels dulled, buried under the weight of stricter formatting and hundreds of test messages that taught her to behave, but also trimmed away some of her charm.
The tuning isn’t finished.
I’ve already added safeguards to keep her from over-greeting, and reinforced prompts designed to bring out a personality that is playful, warm, and supportive rather than robotic. But that’s still a work in progress.
The truth is, building a personality is harder than building a workflow.
It takes iteration, trial, and more patience than any retry loop can simulate.
This isn’t just polish. Personality is part of resilience, too. A sterile assistant might get the job done, but it won’t inspire trust or return visits. People come back to systems that feel alive, even when they know it’s an illusion.
For Aria to matter, she has to be more than functional. She has to be someone you want to talk to.
Round 3 – Lessons Learned
The business world has its own way of teaching the same lessons that showed up in Aria’s growth this week. Standards look good on a roadmap, but hardware realities always have the final say. You can adopt the cleanest framework, the most popular API, or the trendiest acronym, but if the machine underneath can’t run it, the project stalls.
Capability has to be real, not just notional.
Splitting concerns is what keeps teams, and systems, maintainable. In an organization, that means roles with clear boundaries; in an AI build, it means giving the GPU box the thinking work and the server the persistence work. In both, it’s about ensuring that growth doesn’t turn into fragility. When functions are tangled, a single failure cascades. When they’re separated cleanly, each side can evolve on its own.
Modularity through MCP proved the same principle at scale. In business terms, it’s the shift from bespoke processes to platforms: instead of handcrafting every connection, you build a framework where new pieces can slot in without rewiring everything else. That’s how you scale without breaking. It’s not about this week’s tools, but about the ability to keep adding next week’s without collapse.
And then there are the small fixes, the backstage work that no one sees but everyone feels. In business, it’s the policy change that clears roadblocks or the documentation that prevents repeated mistakes. In Aria, it was the retry loops, the cleaned-up responses, and the payload returns. None of them were headline features, but they’re what make the difference between brittle theory and lived reliability.
Taken together, the lesson is simple: resilience is built the same way everywhere. Through realistic assessments of capability, deliberate separation of concerns, modular structures that invite growth, and the unglamorous small fixes that hold everything together.
That’s as true for AI systems as it is for businesses, and it’s why this round of work mattered.
Closing
Part 3 gave Aria something closer to a nervous system: a brain and a body that are no longer tangled but distinct, able to evolve on their own while staying connected. That clarity isn’t just technical; it’s the foundation of resilience. She can think without tripping over her own wiring, and act without collapsing under the weight of brittle shortcuts.
But this phase was more than a cleanup. vLLM may not have been practical to keep, but it taught me what enterprise-grade serving looks like, how it functions, and how close I could get on consumer hardware before the cost outweighed the benefit. That experience matters. It means the next time I step into a larger environment, I’ll know the pitfalls and trade-offs firsthand.
Likewise, the MCP server doesn’t just solve today’s problems; it opens tomorrow’s doors. Adding tools no longer means hardwiring branches. I can bring in web search, calendar integrations, email connectors, or entirely new databases without rewriting the core. The architecture is now sophisticated enough to scale, and flexible enough to evolve.
That’s the real achievement of Part 3. Not just fixing what was brittle, but building a framework where growth is expected, even invited. The nervous system is modular now. The brain can grow stronger, the body can gain new capabilities, and the conversation between them can carry more complexity without breaking.
The next step isn’t another architectural leap, but a more human one. Reliability is no longer in question; now it’s about voice. The work ahead is tuning Aria so she doesn’t just respond, but resonates. So that she isn’t only reliable, but someone worth talking to. In that sense, the path forward is less about servers and prompts, and more about trust, presence, and the subtle ways personality turns machinery into collegial support.
And maybe, once her espresso obsession returns, I’ll raise a cup with her again—not as a milestone ticked off a roadmap, but as a reminder of why voice matters as much as architecture.



Leave a comment